Authoring
Write in markdown, not form fields
A real editor with a live, sanitized preview. Use headings, lists, code blocks, bold and italics, so your cards look the way you wrote them, with no fiddly inputs to fight.
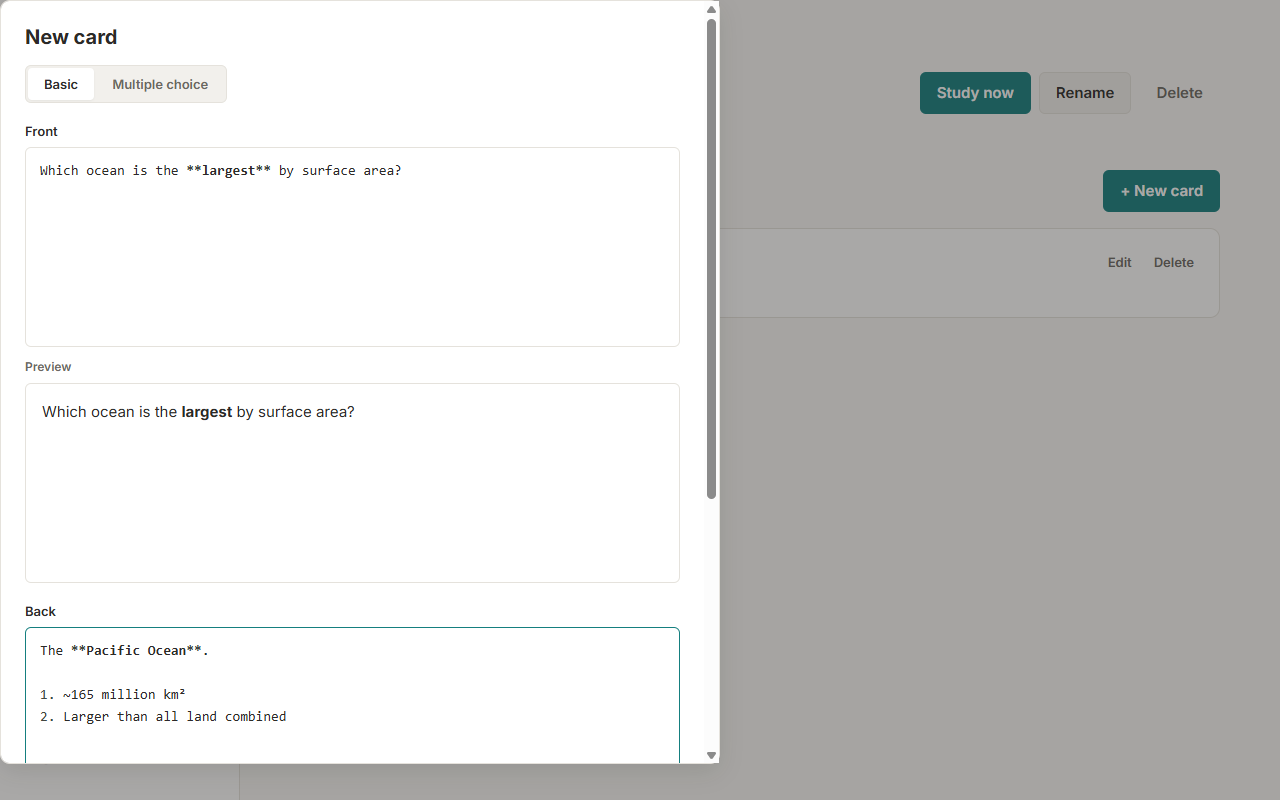
Rouse pairs a fast, clean markdown editor with a proven spaced-repetition scheduler. Write basic, multiple-choice, and cloze cards, then study them anywhere, even offline.
A real editor with a live, sanitized preview. Use headings, lists, code blocks, bold and italics, so your cards look the way you wrote them, with no fiddly inputs to fight.
An Anki-style SM-2 scheduler with learning steps and four grades: Again, Hard, Good, Easy. Cards come due in your own timezone, so nothing surprises you a day early.
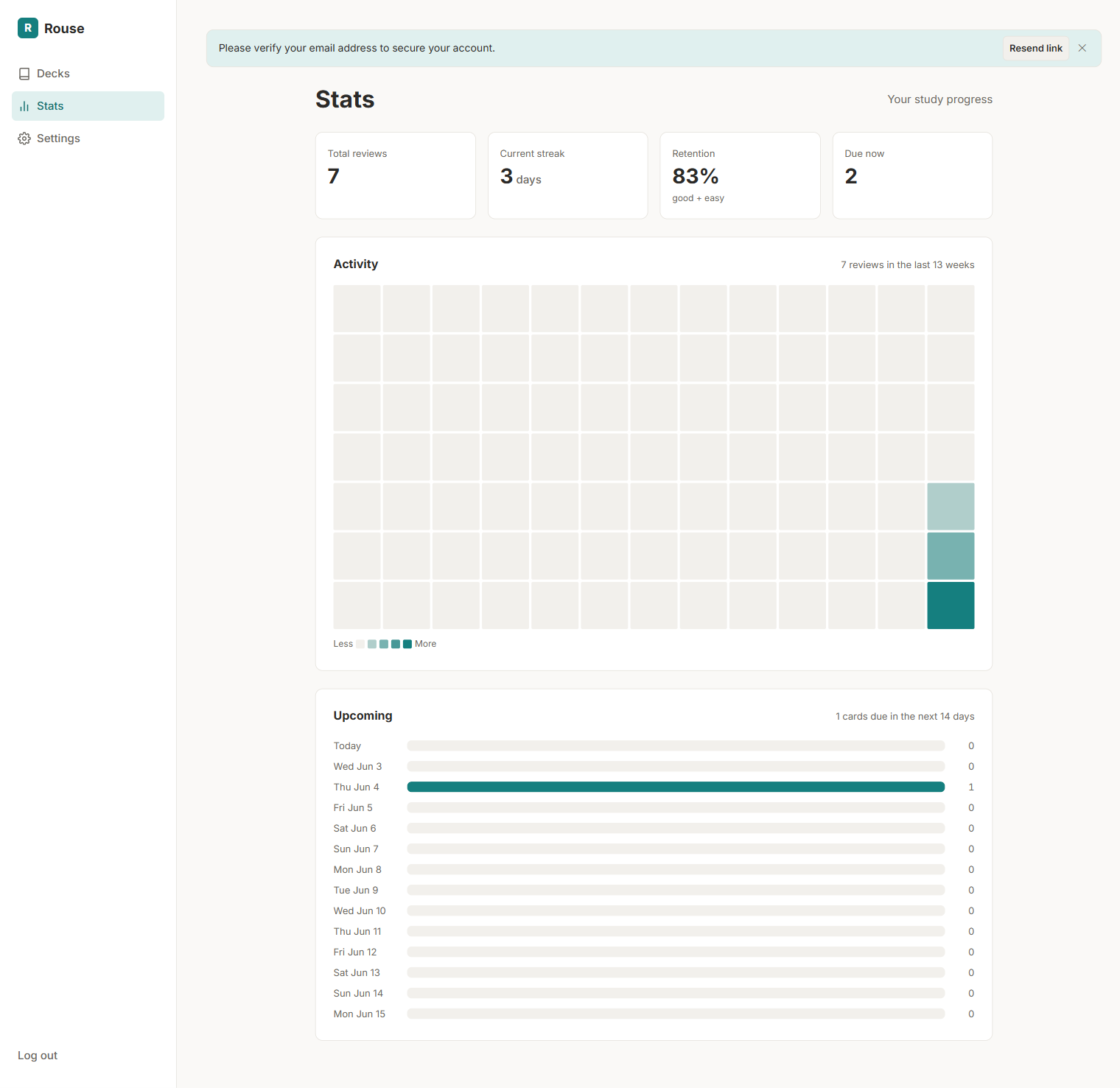
Track your review streak, retention rate, a quarter-long activity heatmap, and a forecast of what's coming due, all private to you, no leaderboards.
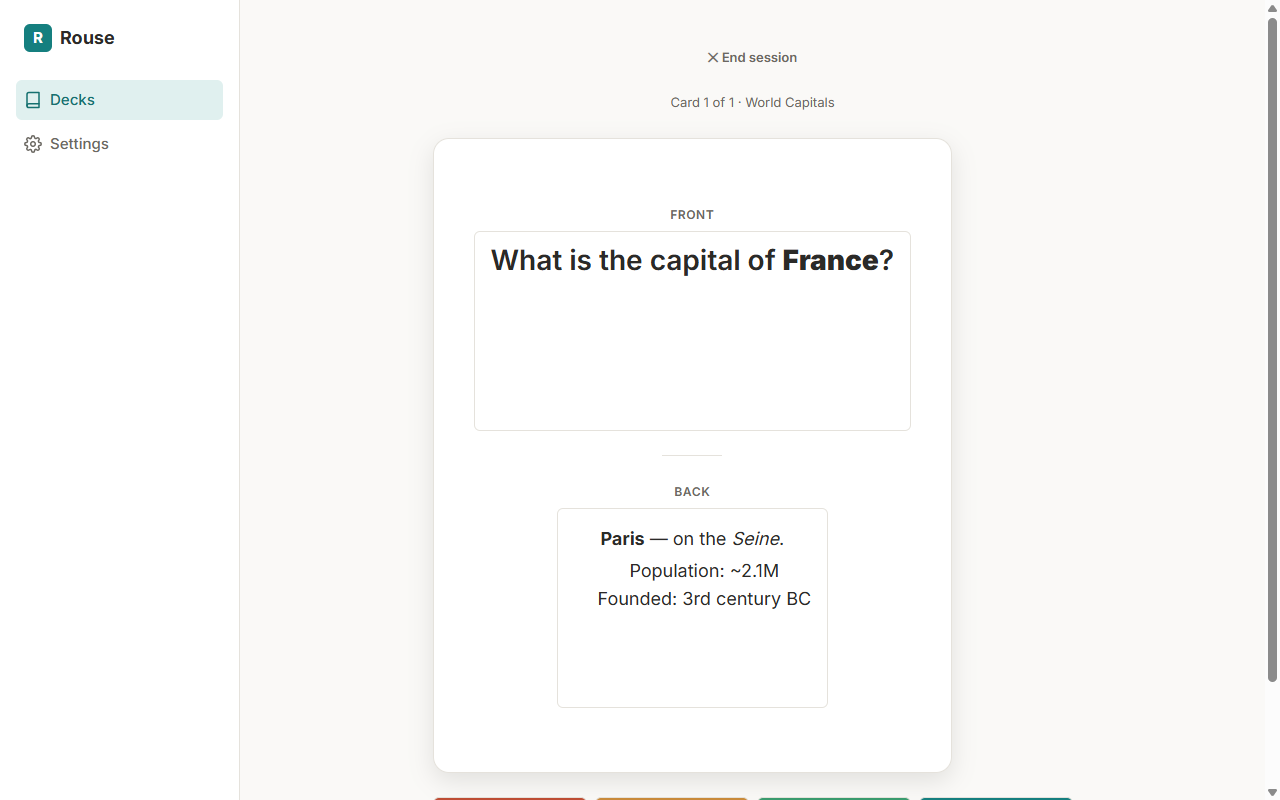
A markdown front and back. Flip to reveal, then grade yourself.
Selectable choices with an optional, collapsible explanation toggle.
Fill-in-the-blank with {{markers}} and optional hints, right inside your markdown.
Free to use. Your decks stay private, and you can install Rouse to your home screen and study offline.
Create your account